zDB: Comparative Genomics Analysis
Protocol provided by Alessia Carrara.
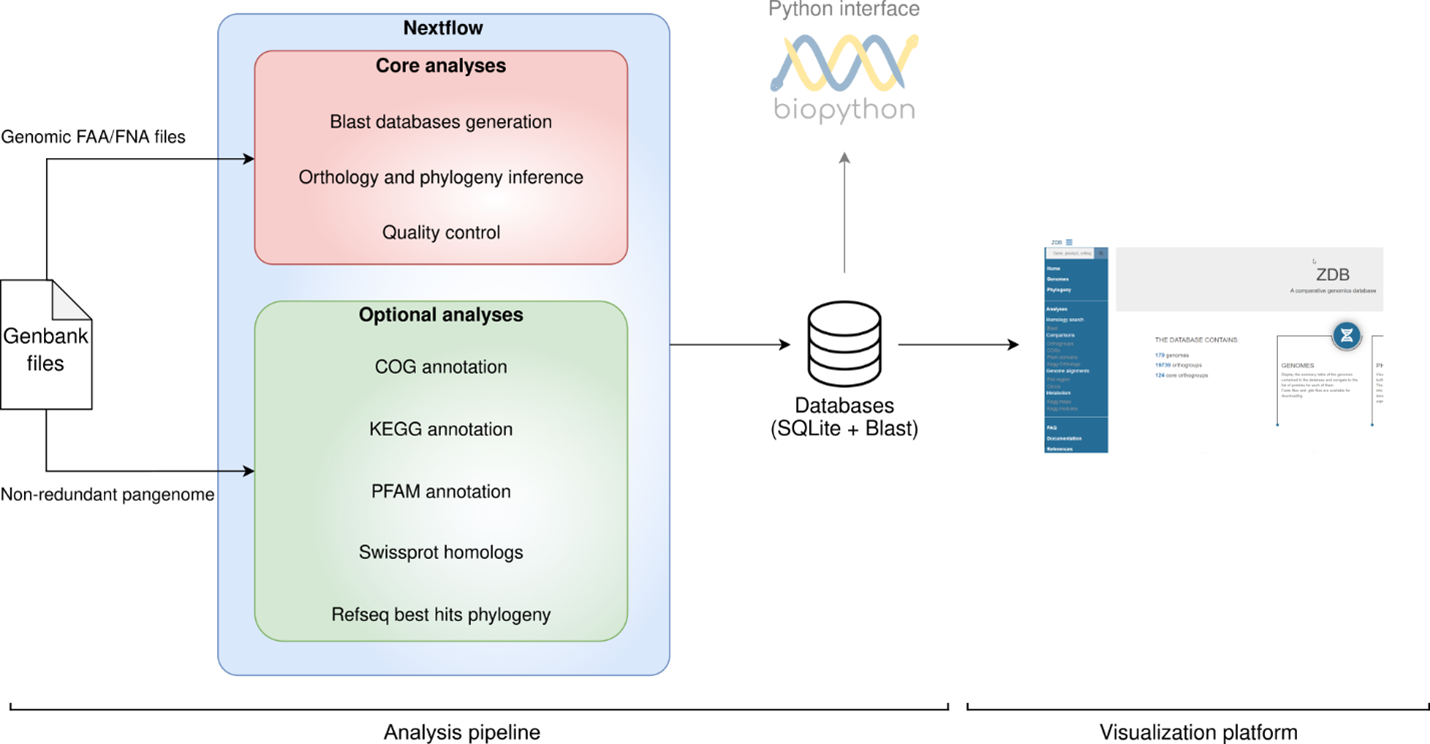
Comparative genomic analyses allow researchers to study and compare the genetic information of different organisms, providing valuable insights into their evolution, biology, and function. However, it is a tedious and time-consuming process that requires specialized knowledge since it relies on the integration of results obtained from multiple tools, further combined for visualization purposes. Therefore, to facilitate genome analysis and comparison, we developed zDB, an application that integrates an analysis pipeline and a visualization platform.
Target Audience
zDB has been developed for both newbies in genomics, who don’t have the experience with bioinformatics tools, and trained bioinformaticians, who would like to invest in a reproducible tool. Therefore, don’t be scared and don’t hesitate to use it!
zDB: Supported Analyses
The analysis pipeline built in zDB can support different types of analysis according to the user’s needs. Indeed, a core set of analyses is run by default, while optional analyses can be separately added.
Orthology inference: identification of orthogroups by OrthoFinder (an orthogroup is the group of genes descended from a single gene in the last common ancestor (LCA) of a group of species).
Phylogenetic reconstructions: phylogeny built based on concatenated alignments of single copy orthologs with FastTree.
Blast search: generate blast databases out of your input genome
COG annotation: label orthologs with the 25 functional categories provided by the COG database (Clusters of Orthologous Groups of proteins) and previously identified based on shared evolutionary origins and functional roles of genes.
KEGG orthologs annotation and pathway completion analysis: label orthologs with molecular interaction pathways and networks provided by the KEGG database (Kyoto Encyclopedia of Genes and Genomes). Obtain insights about the completeness of the identified pathways.
PFAM domains annotation: assign protein domains to orthologs
AMR annotation: annotate genomes with Antimicrobial Resistance genes using AMRFinderPlus.
Virulence factors: annotate genomes with virulence factors from the VFDB.
Genomic islands: identify genomic islands in the genomes.
Swissprot homologs search: look for homologous proteins for each ortholog in the Swiss-Prot database which contains manually curated protein sequences and provides a high level of annotation.
RefSeq homologs search: look for homologous proteins for each ortholog in a comprehensive collection of curated and annotated sequences of a wide range of organisms.
The webinterface then allows exploring the data, notably:
Blast: blast any sequence against your set of genomes.
Venn diagrams: Display venn diagrams of annotations shared or unique to given sets of genomes.
Tabular comparisons: Extract lists of annotations present in a given set of genomes and absent from another, or display a table of presence/absence of annotations in a set of genomes.
Heatmaps: Display a heatmap of the presence of annotations in the genomes.
Accumulation/rarefaction plots: Plots of accumulation/rarefaction of annotations in the set of genomes (pan/core genome)
GWAS: Significant associations between a phenotype and any annotation can be determined.
For more info about the tools and parameters please refer to the methods section of the zDB documentation or the materials and methods section of the manuscript.
Input Files for zDB
Input csv file containing the path to .gbk files.
The requirement of annotated genomes (.gbk files) implies that the user is responsible for the annotation of the genomes. Here are some examples of annotation tools you can use: bakta, prokka, PGAP.
The input genomes (minimum 2) can be publicly available and/or newly sequenced ones.
How to install and run zDB
In the GitHub repository, you can have detailed instructions on how to install and run zDB. Please refer to if you have any problem or you want to get more details. In the meantime, here below is a brief list of all the key steps:
Install zDB and tools to run the analysis and/or web app in containers (recommended).
conda install nextflow=22.10 -c bioconda # install nextflow
conda install zdb -c bioconda # zDB installation
conda install singularity=3.8.4 -c conda-forge # singularity installation
For the installation of docker, please see the Docker documentation.
Download the database(s) needed for the annotation steps (optional).
Select the databases needed for your analysis. The RefSeq database must be downloaded and prepared autonomously.
zdb setup --pfam --swissprot --cog --ko --conda
Run the pipeline.
Add flags according to the annotation you want to get.
RefSeq homologs search significantly slows down the analysis.
All the results will be stored in an SQL database.
zdb run --input=input.csv --ko –cog
Initiate and access the web server.
The terminal will output an IP address where a customized web-based interface built from the SQL database is available. To access the interface, follow this example: If the output looks like this: @155.105.138.249 172.17.0.1 on port 8080, type either 155.105.138.249:8080 or 172.17.0.1:8080 on your web browser to visualize.
Accessibility of the Output
If you want to share your newly generated SQL database you can export it using zdb export command and transfer it to other machines. You may want to transfer it to i) a personal machine for personal usage, ii) a lab machine to host it on an intranet domain and make it accessible to other lab mates, or iii) host it on an internet domain to make it accessible to everyone.
Useful Links to explore zDB by yourself!
This example of the web interface generated via zDB on a dataset of 41 Rickettsiales genomes.
Tips on how to navigate the web interface and interpret your data.